Summary
Facing ETL modernization challenges like brittle jobs, opaque dependencies, and rising cloud bills? PDI’s ETL modernization framework delivers outcomes through six phases: Assess → Prioritize → Plan → Modernize & Orchestrate → Validate & Cutover → Operate & Optimize. We specialize in ETL to ELT migration on modern platforms (Snowflake, BigQuery, Databricks, Azure Synapse), with data quality as code, data governance and lineage, and cost optimization for data pipelines built‑in.
Who should read this
- Data & analytics leaders planning data platform migration or cloud data warehouse migration
- Architects and data engineers driving data pipeline modernization
- Teams moving legacy ETL to ELT and introducing Change Data Capture (CDC), SCD Type 2, and modern data orchestration
Why ETL modernization—and why now
-
Cloud economics & scale: Elastic compute, separation of storage/compute, and MPP SQL change where transforms should run (favoring ELT).
-
From ETL to ELT: Push heavy transforms into the warehouse/lakehouse to simplify ops and improve transparency.
-
Streaming & CDC: Near‑real‑time demands (apps, ML features) push beyond nightly batch; CDC pipelines reduce latency and cost.
-
Governance: Regulations and internal controls require first‑class RBAC/ABAC, masking & PII compliance, with end‑to‑end lineage.
The top ETL modernization challenges (and how to spot them)
1) Hidden complexity in legacy jobs
Symptoms: Thousands of hand‑coded jobs, cron‑style schedules, brittle dependencies.
Risks: Breakage during data platform migration; ballooning rework.
What to do: Auto‑catalog jobs and lineage; classify by complexity, business criticality, and change cadence.
2) Re‑platform vs. re‑architect ambiguity
Symptoms: “Lift‑and‑shift now, fix later.”
Risks: Cloud spend spikes; tech debt persists.
What to do: Use decision trees to choose retain / re‑platform / re‑architect / retire per workload; prefer ETL to ELT migration where feasible.
3) Data quality & parity
Symptoms: “KPIs changed after cutover.”
Risks: Trust erosion.
What to do: Adopt validation and parity testing—row/column counts, checksums, quantile comparisons, and KPI parity baked into CI/CD as data quality as code.
4) Orchestration & observability gaps
Symptoms: Users report failures before alerts do.
Risks: SLA breaches.
What to do: Standardize on modern data orchestration (Apache Airflow) (or equivalent) with retries, backfills, lineage hooks, and SLO dashboards.
5) Governance & security drift
Symptoms: Manual entitlements; ad‑hoc masking rules.
Risks: Audit findings and access sprawl.
What to do: Policy‑as‑code for RBAC/ABAC, masking, and tags; automatic propagation across environments; end‑to‑end data governance and lineage.
6) Cost predictability
Symptoms: Post‑migration cloud bills surprise everyone.
Risks: Program stalls.
What to do: Implement cost optimization for data pipelines with budgets, anomaly alerts, right‑sizing, workload tiers, and caching/materialization strategies.
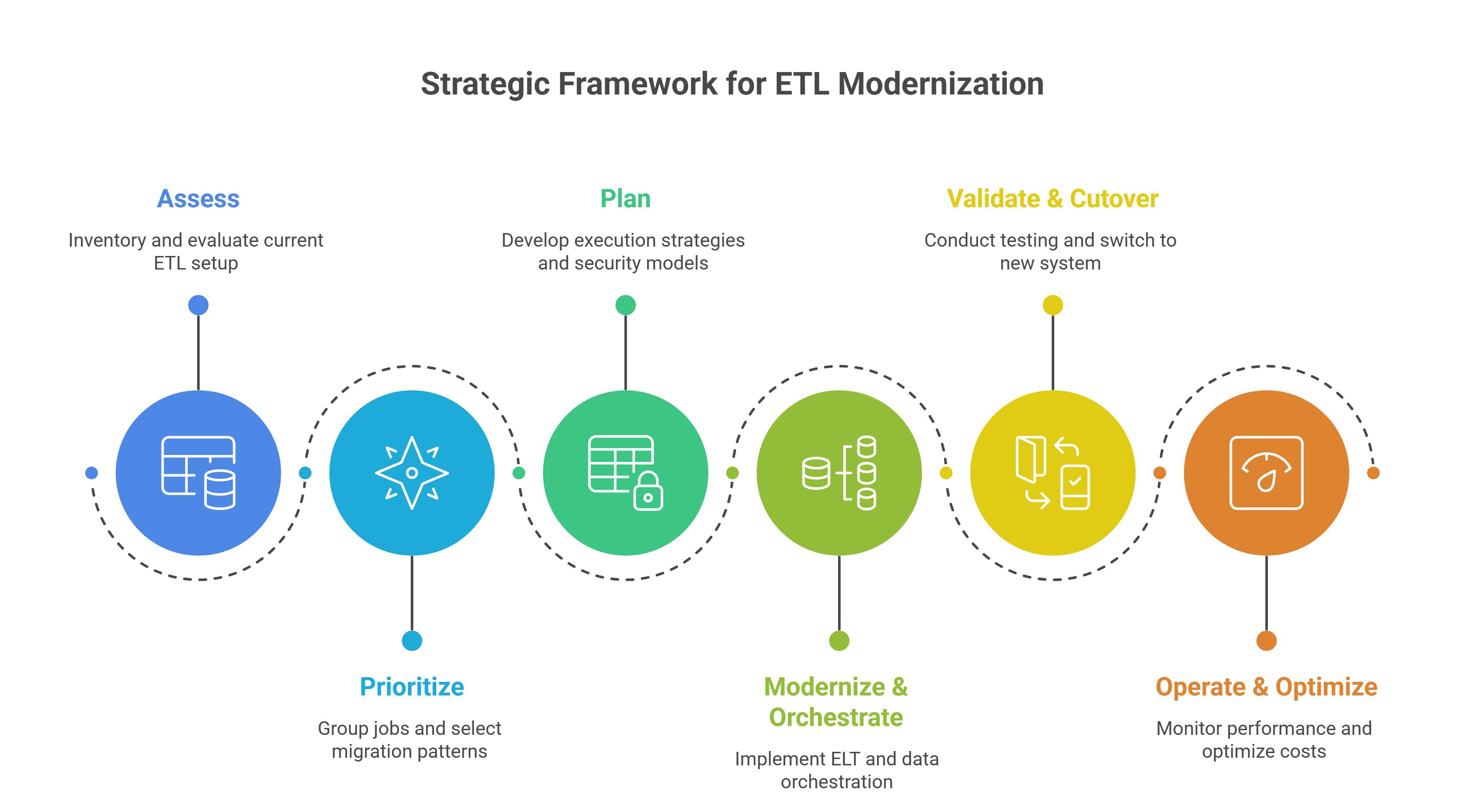
PDI’s Strategic Framework for Successful ETL Modernization
Phase 1 — Assess (what you have, what it’s worth)
Activities
- Inventory sources, targets, jobs, schedules, dependencies, SLAs
- Tag workloads by business criticality (tier 0/1/2), PII/Sensitive, and change cadence
- Capture current TCO and pain points; identify candidates for ETL to ELT migration
Deliverables
- Complete pipeline catalog + lineage map
- Workload scoring (complexity × value × risk)
- Current‑state cost baseline
Phase 2 — Prioritize (what to do first)
Activities
-
Group jobs into migration waves by domain and dependency
-
Apply decision tree: Retain / Re‑platform / Re‑architect / Retire
-
Select patterns (e.g., CDC ingest, SCD Type 2 dims, micro‑batch streaming)
Deliverables
- Group jobs into migration waves by domain and dependency
- Apply decision tree: Retain / Re‑platform / Re‑architect / Retire
- Select patterns (e.g., CDC ingest, SCD Type 2 dims, micro‑batch streaming)
Phase 3 — Plan (how you’ll execute)
Activities
-
Environment topology (dev/test/pre‑prod/prod) and CI/CD branching
-
Security model: RBAC/ABAC, masking & PII compliance, key management
-
Cutover strategy: parallel run, backfill, checkpointing, rollback
Deliverables
- Migration runbook (below)
- Test plan + acceptance criteria (parity, performance, cost)
- Resource model (team RACI, calendar)
Phase 4 — Modernize & Orchestrate (build it right)
Activities
- Refactor to ELT on Snowflake, BigQuery, Databricks lakehouse, or Azure Synapse
- Standardize ingestion (batch, streaming/CDC) with schema evolution controls
- Implement data orchestration (Apache Airflow) with retries/backfills, SLA monitors, and lineage capture
- Introduce data quality as code—tests versioned and runnable in CI
Deliverables
-
Parameterized pipelines and reusable macros
-
Orchestrator DAGs with documented SLAs and alerts
-
Data quality test suite integrated into CI/CD
Phase 5 — Validate & Cutover (prove it works)
Activities
- Validation and parity testing: counts, checksums, quantiles, KPI parity
- Performance tests under production‑like loads
- Parallel runs with controlled audience switchover
Deliverables
- Signed test results; variance threshold approvals
- Cutover checklist completion; rollback rehearsal
- Post‑cutover monitoring dashboards
Phase 6 — Operate & Optimize (make it economical)
Activities
- Cost optimization for data pipelines: budgets, anomaly alerts, right‑sizing/auto‑scaling
- SLO dashboards (freshness, throughput, success rates) and error budgets
- Governance posture reviews; access recertification; lineage‑based impact analysis
Deliverables
-
Monthly cost & reliability report
-
Optimization backlog (partitioning, clustering, materialization, caching),
-
Continuous improvement cadence
Reference architecture patterns (choose by need)
-
Batch ELT to Cloud DW/Lakehouse: Landing → Staging → Curated with push‑down SQL on Snowflake/BigQuery/Databricks/Azure Synapse.
-
Streaming/CDC: Log‑based Change Data Capture (CDC) → Stream processing → Upserts/Merge; exactly‑once where needed.
- Hybrid: Batch dimensions + streaming facts; SCD Type 2 for dimensional history.
- Reverse ETL: Curated data → SaaS apps under governance and masking.
Governance spine: central catalog, policy‑as‑code for RBAC/ABAC, masking, and tags; stitched data governance and lineage from orchestrator + catalog + warehouse.
Decision tree (per workload)
-
Retain: Low value, stable, compliant → keep and monitor.
-
Re‑platform: Valuable, low complexity → 1:1 mapping to modern equivalents.
-
Re‑architect: High value/complex → re‑model to domain tables; adopt ELT/streaming patterns.
-
Retire: Redundant/unused → decommission to fund priority work.
Migration runbook (mini)
Pre‑cutover
- Final backfill window agreed
- Validation and parity testing green in pre‑prod
- Access controls validated; secrets rotated
- Monitoring & alerts verified in prod
Cutover
- Freeze legacy writes for the window
- Backfill delta; validate counts, checksums, KPI parity
- Switch read endpoints via feature flag/connection string
- 24–72h heightened monitoring
Rollback (if needed)
-
Repoint consumers to legacy endpoints
-
Reconcile deltas queued during attempt
-
RCA; tighten tests or logic
Example RACI (Wave 1)
|
Activity
|
Product Owner
|
Data Eng
|
Platform Eng
|
Sec/GRC
|
QA/Testing
|
|
Inventory & scoring
|
A
|
R
|
C
|
C
|
C
|
|
Pattern selection
|
A
|
R
|
C
|
C
|
C
|
|
Pipeline refactor
|
C
|
R
|
A
|
C
|
C
|
|
DQ test authoring
|
C
|
R
|
C
|
C
|
A
|
|
Cutover approval
|
A
|
R
|
C
|
C
|
C
|
A=Accountable, R=Responsible, C=Consulted
KPIs & acceptance criteria
-
Freshness SLO: 99% of tables meet target latency
-
Reliability: ≥99% on‑time runs; ≤0.1% failure rate with auto‑retry
-
Cost: Cost per TB transformed and per successful run trending down MoM
-
Quality: <0.5% variance on critical KPIs vs. legacy during parallel run
-
DevX: Lead time for new pipeline ≤2 days; MTTR ≤30 minutes
ETL modernization checklist & best practices
Foundations
- Pipeline inventory & lineage captured
- Workloads scored and waved
- RBAC/ABAC, masking & PII compliance defined as code
- Environments & CI/CD ready
Build
- Patterns chosen (ELT/CDC/streaming) per workload
- Data orchestration (Apache Airflow) DAGs with retries/backfills
- Data quality as code tests authored & versioned
- Catalog & lineage integration complete
Cutover
- Parallel run variance within thresholds
- Sign‑offs from data owners & downstream owners
- Rollback rehearsed
- Monitoring dashboards live
Operate
-
Budgets & anomaly alerts configured
-
SLOs & error budgets defined
-
Monthly optimization cadence in place
How PDI accelerates your ETL modernization
-
Assessment accelerators: Auto‑discover jobs, dependencies, and lineage; scoring templates and TCO baselining
-
Pattern library: Ingestion/ELT/CDC modules; SCD Type 2 strategies; orchestration templates
-
Quality & governance: Data quality as code, policy‑as‑code, RBAC/ABAC; end‑to‑end data governance and lineage
-
Cost & SLO guardrails: Dashboards and budget alerts for cost optimization for data pipelines
-
Change management: Runbooks, playbooks, and enablement that stick after go‑live
Ready for a 2‑week readiness assessment with a wave plan, cost model, and risk map? Contact PDI to get started.
Analyst Insights: What the Industry Says About ETL Modernization
Industry analysts consistently emphasize that successful modernization blends technology, operating model, and economics. Here’s a consolidated view you can share with sponsors and architecture boards, with source links for credibility.
Gartner: Modern data management is composable, automated, and governed
-
Composable data architecture over monoliths: modular services for ingestion, transformation, quality, and governance that evolve independently (see Gartner’s overview of Data Fabric). Source
-
Active metadata & lineage as control planes: power observability, impact analysis, and automated policy enforcement (Gartner’s guidance on moving from passive to active metadata). Source
-
DataOps & FinOps as program guardrails; cloud‑native integration patterns (streaming/CDC, ELT pushdown) repeatedly appear in Top Trends in Data & Analytics. Source
Implication for PDI clients: Prioritize policy‑as‑code, data quality as code, and lineage early; design your platform as a set of replaceable capabilities, not a single vendor lock‑in.
McKinsey: Treat data pipelines as products with clear value and ownership
-
Product operating model: Pipelines and semantic layers owned by cross‑functional teams with roadmaps and SLAs—“manage data like a product.” Source
-
Business‑backlog alignment and scaling data products to measurable outcomes (cycle‑time, conversion, risk). Source
-
FinOps as code to manage cloud costs alongside delivery velocity. Source
Implication for PDI clients: Use PDI’s workload scoring and wave plan to target value; formalize ownership (RACI) and publish SLAs/SLOs.
IDC: Hybrid reality, automation, and cost governance at scale
-
Hybrid/multi‑cloud data estates are the norm; portability and standards matter. Source
-
Automation first: code conversion, CI/CD for data, and orchestrated testing reduce risk and cost. Source
-
Economic discipline: usage visibility, right‑sizing, and policy guardrails to prevent overruns post‑migration. Source
Implication for PDI clients: Instrument from day one (cost budgets, anomaly alerts, lineage‑aware monitoring) and design for portability across Snowflake/BigQuery/Databricks/Azure Synapse.
Forrester (also relevant): From ETL to ELT and real‑time activation
-
ELT + pushdown as default for cloud MPP/lakehouse performance and maintainability aligns with Forrester’s coverage on modern analytics and real‑time activation. Source
-
Pragmatic governance: federated, policy‑driven controls embedded in developer workflows; see Forrester’s Data Governance hub. Source
Implication for PDI clients: Standardize patterns (ELT, CDC, SCD2, reverse ETL) and codify guardrails in templates so teams can move fast safely.
How to use these insights in your program
Map analyst guidance to PDI’s framework:
-
Assess/Prioritize: Score by business value and risk; document lineage and policy exposure (Gartner/IDC).
-
Plan: Establish product‑team ownership and define SLAs/SLOs with cost targets (McKinsey).
-
Modernize & Orchestrate: Implement ELT/CDC patterns with active metadata and automated tests (Gartner/Forrester).
-
Validate & Cutover: Enforce KPI parity and rehearse rollback to maintain trust (McKinsey).
-
Operate & Optimize: Put FinOps and observability dashboards in place; review posture monthly (IDC).
Executive takeaway: Analysts converge on the same theme—modernization succeeds when you combine composable architecture, product‑team ownership, and cost & quality guardrails. PDI’s accelerators and framework operationalize exactly that.
FAQs
What’s the difference between ETL and ELT in modernization?
ETL transforms before loading; ELT loads data first and transforms inside the cloud engine. ELT typically wins for maintainability, performance, and cost transparency—especially with Snowflake, BigQuery, Databricks, or Azure Synapse.
Do we need to migrate everything?
No. Use the decision tree: retain stable low‑value jobs, re‑platform quick wins, re‑architect high‑value complex areas, and retire the rest.
How do we prove parity and rebuild trust?
Automate validation and parity testing: counts, checksums, quantiles, and KPI parity. Run parallel for a defined window; cut over with a rehearsed rollback.
What’s the fastest path to value?
Target a business domain with clear sponsorship, measurable KPIs, and stable upstreams for Wave 1—prove value, then scale the template.



.png@width=352&name=10202023_042524_aws-vs-azure-vs-gcp (1).png)